Optimizing Millions: A Case Study on Crafting High-Impact Open-Source SIMD Code
There is much to criticize about the public school system. One of the biggest failings is that it doesn’t teach that there is no such thing as a free lunch. In real life, time is always at a premium.
Throughout the SIMD projects I did with Daniel Lemire, there was no hard deadline—but much like I set targets when I enter a workout session, I still set daily and weekly targets for myself. I often asked myself “if I try this, how much time will it take me? Am I really doing the simplest possible thing? Is there anything dumber I might have overlooked?”.
I hope to provide a frame of reference by outlining how I ported the Base64 decoding algorithm from simdutf to C# during the summer of 2024. Everything is time stamped if you take a look at the closed PRs—their names are descriptive so it should not be too difficult to follow.
Step #0: Find a problem people care about that we can plausibly improve upon
Base64 is a way to encode any arbitrary binary data into ASCII text. The encoding makes the data 30% bigger, but this is offset by its usefulness due to the ubiquitousness of ASCII. For example, a web developer can embed an image into a web page without making an extra network request.
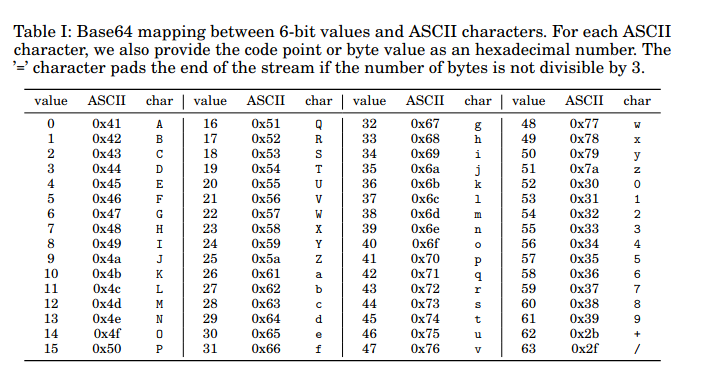 Source: Muła & Lemire, 2019. See p.2
Source: Muła & Lemire, 2019. See p.2
Daniel related to me that the Microsoft team already had a fast way to encode but would be interested in the decoding part.
In this particular case, there was not only one but two whole papers detailing the approaches as well as a blog post and working C++ implementation as part of the simdutf library, already in use by millions.
Since we already had good results from SIMDUnicode, this proved to be an excellent candidate for a summer project.
Step #1: Reading other people’s Code
The first order of business was to get situated. I did a quick first pass of the paper and then a second pass with a highlighter and white board. As needed, I glanced at the C++ implementation if something was unclear and switched back and forth.
I then turned my attention to the runtime. My objective when reading the runtime was to:
- Ascertain exactly what the function our code was replacing was doing. In particular, I noted the function signature and whether the function also performed any auxiliary tasks. In this case, the Runtime’s functions tended to return both bytes consumed and written regardless of outcomes, while simdutf’s returned one or the other if there was an error.
- Look for cues as to what was permissible and what wasn’t. (I already did this while working on SIMDUnicode so I only skimmed the Runtime code.)
Step #3: Writing scalar code
My next task was to write a scalar version to provide a baseline—partly for speed but mostly for correctness. Scalar code is, by far, easier to debug than SIMD code.
Now, as you might have guessed, I’m a big fan of functional programming for the lessons it teaches; however, just like there is no such thing as a free lunch, there is no such thing as zero-cost abstractions.
You are never quite 100% sure how the compiler will translate your code. A further abstraction might lead to more convoluted logic on the part of the compiler. Part of my job was to remove as many abstractions as possible without “throwing the baby out with the bathwater.”
For example, C++ has templates while C# has generics—runtime constructs that are probably too slow for use in a hot loop. In practice, the only place I could realistically use them was in benchmarks or tests. Instead, I ended up copy-pasting code.
Another example: the current “meta” in programming is to use smart pointers. In C++, guidelines strongly suggest using smart pointers almost always. In the broader C# community, the by-the-book answer is to keep everything in MemoryMarshall and avoid raw pointers. However, when reading MSFT’s solution to UTF8 validation, I saw raw pointers in use, so I knew it was not only acceptable when appropriate but sometimes necessary. In short, MemoryMarshall is C#’s answer to smart pointers—but there are differences.
These very small decisions, made throughout the project, were very circumstantial.
In order to understand the next section, it is helpful to get an overview of the scalar code:
 Source: Muła & Lemire, 2018. See p.4
Source: Muła & Lemire, 2018. See p.4
This was the result. Note it isn’t perfect—I would come back and polish it afterward as needed.
Step #4: Writing tests
Here comes the unglamorous part. I ported the C++ tests to C#. The existing tests covered each conditional branch in the code, plus several brute force tests. I already knew from experience that the brute force test might not catch every single issue.
I combined the tests into one step to create a coherent narrative, although in practice I would write tests as needed. It’s hard to think of every possible state your code may be in and get it 100% correct on the first try.
I did not use a debugger—at best, they are clunky, and it’s faster and more resilient to write tests if you really want to see what's inside a SIMD vector.
Debugging and ensuring correctness was the bulk of the work; it was the biggest wildcard in terms of time management.
Step #5: Writing benchmarks
This step can be a bit more involved. For SIMDUnicode, since UTF8 validation is part of the core, permissions prevented me from simply calling .NET’s validation function from anywhere. I ended up copy-pasting the code from .NET into our project—a laborious process since helper functions were spread across several files in the runtime.
This was not the case here. For our purposes, the DotnetBenchmark library proved sufficient.
Step #6: Writing SIMD code
I then wrote the kernels for the SSE, AVX2 , and AVX-512 architectures.
I will briefly summarize the AVX-2 SIMD algorithm. In a nutshell, we convert Base64 to ASCII by adding a certain offset to the encoded character:
 Source: Muła & Lemire, 2018. See p.10
Source: Muła & Lemire, 2018. See p.10
We can deduce this from only the high and low nibbles:
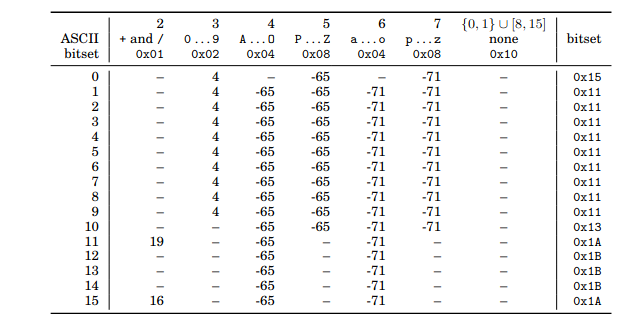 Source: Muła & Lemire, 2018. See p.15
Source: Muła & Lemire, 2018. See p.15
Given a SIMD vector, the algorithm must first check for error and determine the offset:
-
It uses a shift instruction (
mm256_srli_epi32) to extract the high nibble of each byte. -
It uses a compare-equal instruction (
mm256_compeq_epi8) to check for the presence of a “/” character. -
It uses a shuffle intrinsic (
mm256_shuffle_epi8) to compare the vector against several lookup tables—once to get the offset and twice to check the high and low nibbles for errors, OR’ing them together. - It then uses a testz instruction to see if that step yielded any errors.
If no errors are found, it then:
- Uses
vpmaddubswto pack data within 16-bit words. - Uses
vpmaddwdto pack data within 32-bit words. - Uses
vpshufbto pack data within 128-bit lanes. - Packs the 24 bytes into a 256-bit vector using
vpermd.
The C++/C# code differs from the paper in that further optimizations were made. I’m oversimplifying here, but the overall idea is:
Suppose that X, Y, and Z are natural numbers with X > Y > Z. Then:
- If there are X bytes remaining, the SIMD routine uses a buffer and loops until it reaches Y.
- If there are Y bytes remaining, it executes SIMD code without looping (since very little remains).
- If there are Z bytes remaining, it falls back to scalar code.
- If there is an error, it switches back to scalar code to locate it.
Although the structure wasn’t exactly the same for every project, it was similar in nature. The transition between these steps is often a prime candidate for errors.To shamelessly namedrop:
“A large fraction of the flaws in software development are due to programmers not fully understanding all the possible states their code may execute in.”
Of course, you can never completely avoid these pitfalls in low-level programming: this is just how a computer works , but here is an example where state led me on a wild goose chase:
For example, here’s a GitHub pull request that illustrates one such issue:
One benchmark was failing due to a sequence in the test file email.txt:
0x6D, 0x6A, 0x6D, 0x73, 0x41, 0x71, 0x39, 0x75, 0x76, 0x6C, 0x77, 0x48, 0x20, 0x77, 0x33, 0x53At first I suspected the benchmark, but after consulting a performance engineering book and reviewing my code carefully, I discovered I had miscast an argument: I had difficulty spotting it because it only triggered if the buffer was (IIRC) only partially full.
Another difficulty was that there isn’t a one-to-one mapping from Intel intrinsics to C# functions. Although C#’s SIMD handling is mostly intuitive, some parts aren’t documented, forcing me to make educated guesses—which sometimes led to typos or incorrect assumptions. In this case, the error only triggered when the buffer in step A was only partially filled.
Performance Work
Performance-wise, I followed best practices but was still unable to beat the Runtime. I tried every trick I knew yet couldn’t pinpoint why.
This is where technical debt caught up with me—or perhaps it was a lack of imagination. In C#, I coded much as I would in C or C++, but there is a big difference: the C/C++ compilers are more lenient when it comes to performance.
To see why, consider what Daniel did:
For example, instead of writing:
// Span buffer = stackalloc byte[32];
Span buffer = new byte[] { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
In the assembly code, we can see the written-out array avoids using the stack altogether.
Another optimization involved helping the compiler by copy-pasting code. For instance, Daniel moved the isUrl parameter to an outer function:
public unsafe static OperationStatus DecodeFromBase64SSE(
ReadOnlySpan source,
Span dest,
out int bytesConsumed,
out int bytesWritten,
bool isUrl = false)
{
if (isUrl)
{
return InnerDecodeFromBase64SSEURL(source, dest, out bytesConsumed, out bytesWritten);
}
else
{
return InnerDecodeFromBase64SSERegular(source, dest, out bytesConsumed, out bytesWritten);
}
}
Daniel commented: ““The 'email' dataset may not show any difference, but it seems that there is a clear difference in the swedenzonebase.txt case. I am not 100% sure why that is,it is likely that the dynamic parameter increases the function call overhead (the swedenzonebase.txt is made of repeated calls over short strings.””
In short, the code tells the compiler, “These are two distinct things; you don’t need to treat them as one giant search space.”
Yet another optimization replaced a check in the scalar function:
(x = d0[*src] | d1[src[1]] | d2[src[2]] | d3[src[3]]) < 0x01FFFFFF
For example, consider the following implementation:
(x = isUrl ? Base64Url.GetD(src) : Base64Default.GetD(src)) < 0x01FFFFFF
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static unsafe uint GetD(char* src)
{
if ((src[0] | src[1] | src[2] | src[3]) > 255)
{
return 0x01ffffff;
}
Span b = new byte[] { (byte)src[0], (byte)src[1], (byte)src[2], (byte)src[3] };
fixed (byte* p = b)
{
return GetD(p);
}
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static unsafe uint GetD(byte* src)
{
internal static readonly uint[] d0 = new uint[256] {
ReadOnlySpan d0 = new uint[256] {
0x01ffffff, 0x01ffffff, 0x01ffffff, 0x01ffffff, 0x01ffffff, 0x01ffffff,
// - snip -
0x01ffffff, 0x01ffffff, 0x01ffffff, 0x01ffffff};
//snip tables d1,d2,d3
ref uint tableRef0 = ref MemoryMarshal.GetReference(d0);
ref uint tableRef1 = ref MemoryMarshal.GetReference(d1);
ref uint tableRef2 = ref MemoryMarshal.GetReference(d2);
ref uint tableRef3 = ref MemoryMarshal.GetReference(d3);
return Unsafe.AddByteOffset(ref tableRef0, (nint)(src[0])) | Unsafe.AddByteOffset(ref tableRef1, (nint)(src[1])) | Unsafe.AddByteOffset(ref tableRef2, (nint)(src[2])) | Unsafe.AddByteOffset(ref tableRef3, (nint)(src[3]));
}
Here the idea is to add a mini-fast path to avoid the tables altogether when possible. When you add up several such micro-optimizations, the difference can be significant.
Conclusion
This concludes my series of articles on the year and a half capstone project. I hope that this case study provided a better understanding of what such a project entails.
There are still aspects that could be improved—for example, one could argue that the most important step is step zero, which I only briefly mentioned. That’s a topic for a future blog post.